Up until now, we haven't utilized any of the expressive non-linear power of neural networks - all of our simple one layer models corresponded to a linear model such as multinomial logistic regression. These one-layer models had a simple derivative. We only had one set of weights the fed directly to our output, and it was easy to compute the derivative with respect to these weights. However, what happens when we want to use a deeper model? What happens when we start stacking layers?

No longer is there a linear relation in between a change in the weights and a change of the target. Any perturbation at a particular layer will be further transformed in successive layers. So, then, how do we compute the gradient for all weights in our network? This is where we use the backpropagation algorithm.
Backpropagation, at its core, simply consists of repeatedly applying the chain rule through all of the possible paths in our network. However, there are an exponential number of directed paths from the input to the output. Backpropagation's real power arises in the form of a dynamic programming algorithm, where we reuse intermediate results to calculate the gradient. We transmit intermediate errors backwards through a network, thus leading to the name backpropagation. In fact, backpropagation is closely related to forward propagation, but instead of propagating the inputs forward through the network, we propagate the error backwards.
Most explanations of backpropagation start directly with a general theoretical derivation, but I’ve found that computing the gradients by hand naturally leads to the backpropagation algorithm itself, and that’s what I’ll be doing in this blog post. This is a lengthy section, but I feel that this is the best way to learn how backpropagation works.
I’ll start with a simple one-path network, and then move on to a network with multiple units per layer. Finally, I’ll derive the general backpropagation algorithm. Code for the backpropagation algorithm will be included in my next installment, where I derive the matrix form of the algorithm.
Examples: Deriving the base rules of backpropagation
For a single unit in a general network, we can have several cases: the unit may have only one input and one output (case 1), the unit may have multiple inputs (case 2), or the unit may have multiple outputs (case 3). Technically there is a fourth case: a unit may have multiple inputs and outputs. But as we will see, the multiple input case and the multiple output case are independent, and we can simply combine the rules we learn for case 2 and case 3 for this case.
I will go over each of this cases in turn with relatively simple multilayer networks, and along the way will derive some general rules for backpropagation. At the end, we can combine all of these rules into a single grand unified backpropagation algorithm for arbitrary networks.
Case 1: Single input and single output
Suppose we have the following network:

A simple "one path" network.
By now, you should be seeing a pattern emerging, a pattern that hopefully we could encode with backpropagation. We are reusing multiple values as we compute the updates for weights that appear earlier and earlier in the network. Specifically, we see the derivative of the network error, the weighted derivative of unit $k$'s output with respect to $s_k$, and the weighted derivative of unit $j$'s output with respect to $s_j$.
So, in summary, for this simple network, we have: $$ \begin{align} \Delta w_{i\rightarrow j} =&\ -\eta\left[ \color{blue}{(\hat{y}_i-y_i)}\color{red}{(w_{k\rightarrow o})(\sigma(s_k)(1-\sigma(s_k)))}\color{OliveGreen}{(w_{j\rightarrow k})(\sigma(s_j)(1-\sigma(s_j)))}(x_i) \right]\\ \Delta w_{j\rightarrow k} =&\ -\eta\left[ \color{blue}{(\hat{y}_i-y_i)}\color{red}{(w_{k\rightarrow o})\left( \sigma(s_k)(1-\sigma(s_k)\right)}(z_j)\right]\\ \Delta w_{k\rightarrow o} =&\ -\eta\left[ \color{blue}{(\hat{y_i} - y_i)}(z_k)\right] \end{align} $$
Case 2: Handling multiple inputs
Consider the more complicated network, where a unit may have more than one input:
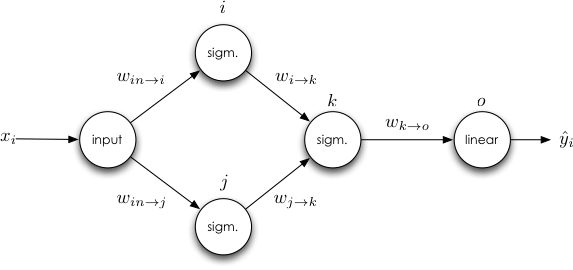
Here we see that the update for $w_{i\rightarrow k}$ does not depend on $w_{j\rightarrow k}$'s derivative, leading to our first rule: The derivative for a weight is not dependent on the derivatives of any of the other weights in the same layer. Thus we can update weights in the same layer in isolation. There is a natural ordering of the updates - they only depend on the values of other weights in the same layer, and (as we shall see), the derivatives of weights further in the network. This ordering is good news for the backpropagation algorithm.
Case 3: Handling multiple outputs
Now let's examine the case where a hidden unit has more than one output.
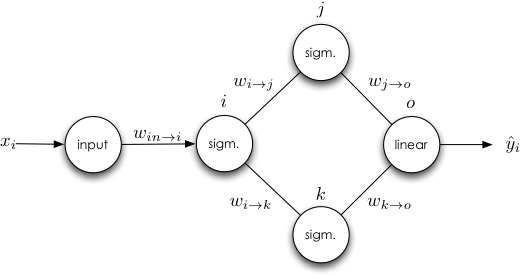
There are two things to note here. The first, and most relevant, is our second derived rule: the weight update for a weight leading to a unit with multiple outputs is dependent on derivatives that reside on both paths.
But more generally, and more importantly, we begin to see the relation between backpropagation and forward propagation. During backpropagation, we compute the error of the output. We then pass the error backward and weight it along each edge. When we come to a unit, we multiply the weighted backpropagated error by the unit's derivative. We then continue backpropagating this error in the same fashion, all the way to the input. Backpropagation, much like forward propagation, is a recursive algorithm. In the next section, I introduce the notion of an error signal, which allows us to rewrite our weight updates in a compact form.
Error Signals
We define the recursive error signal at unit $j$ as: $$ \begin{align} \delta_j =&\ \frac{\partial E}{\partial s_j} \end{align} $$ In layman's terms, it is a measure of how much the network error varies with the input to unit $j$. Using the error signal has some nice properties - namely, we can rewrite backpropagation in a more compact form. To see this, let's expand $\delta_j$: $$ \begin{align} \delta_j =&\ \frac{\partial E}{\partial s_j}\\ =&\ \frac{\partial}{\partial s_j}\frac{1}{2}(\hat{y} - y)^2\\ =&\ (\hat{y} - y)\frac{\partial \hat{y}}{\partial s_j} \end{align} $$ Consider the case where unit $j$ is an output node. This means that $\hat{y} = f_j(s_j)$ (if unit $j$'s activation function is $f_j(\cdot)$), so $\frac{\partial \hat{y}}{\partial s_j}$ is simply $f_j'(s_j)$, giving us $\delta_j = (\hat{y} - y)f'_j(s_j)$.
Otherwise, unit $j$ is a hidden node that leads to another layer of nodes $k\in \text{outs}(j)$. We can expand $\frac{\partial \hat{y}}{\partial s_j}$ further, using the chain rule: $$ \begin{align} \frac{\partial \hat{y}}{\partial s_j} =&\ \frac{\partial \hat{y}}{\partial z_j}\frac{\partial z_j}{\partial s_j}\\ =&\ \frac{\partial \hat{y}}{\partial z_j}f_j'(s_j) \end{align} $$ Take note of the term $\frac{\partial \hat{y}}{\partial z_j}$. Multiple units depend on $z_j$, specifically, all of the units $k\in\text{outs}(j)$. We saw in the section on multiple outputs that a weight that leads to a unit with multiple outputs does have an effect on those output units. But for each unit $k$, we have $s_k = z_jw_{j\rightarrow k}$, with each $s_k$ not depending on any other $s_k$. Therefore, we can use the chain rule again and sum over the output nodes $k\in\text{outs}(j)$: $$ \begin{align} \frac{\partial \hat{y}}{\partial s_j} =&\ f_j'(s_j)\sum_{k\in\text{outs}(j)} \frac{\partial \hat{y}}{\partial s_k}\frac{\partial s_k}{\partial z_j}\\ =&\ f_j'(s_j)\sum_{k\in\text{outs}(j)} \frac{\partial \hat{y}}{\partial s_k}w_{j\rightarrow k} \end{align} $$ Plugging this equation back into the function $\delta_j = (\hat{y} - y) \frac{\partial \hat{y}}{\partial s_j}$, we get: $$ \begin{align} \delta_j =& (\hat{y} - y)f_j'(s_j)\sum_{k\in\text{outs}(j)} \frac{\partial \hat{y}}{\partial s_k}w_{j\rightarrow k} \end{align} $$ Based on our definition of the error signal, we know that $\delta_k = (\hat{y} - y) \frac{\partial \hat{y}}{\partial s_k}$, so if we push $(\hat{y} - y)$ into the summation, we get the following recursive relation: $$ \begin{align} \delta_j =& f_j'(s_j)\sum_{k\in\text{outs}(j)} \delta_k w_{j\rightarrow k} \end{align} $$ We now have a compact representation of the backpropagated error. The last thing to do is tie everything together with a general algorithm.
The general form of backpropagation
Recall the simple network from the first section:


The last thing to consider is the case where we use a minibatch of instances to compute the gradient. Because we treat each $y_i$ as independent, we sum over all training instances to compute the full update for a weight (we typically scale by the minibatch size $N$ so that steps are not sensitive to the magnitude of $N$). For each separate training instance $y_i$, we add a superscript $(y_i)$ to the values that change for each training example: $$ \begin{align} \Delta w_{i\rightarrow j} =&\ -\frac{\eta}{N} \sum_{y_i} \delta_j^{(y_i)}z_i^{(y_i)} \end{align} $$ Thus, the general form of the backpropagation algorithm for updating the weights consists the following steps:
- Feed the training instances forward through the network, and record each $s_j^{(y_i)}$ and $z_{j}^{(y_i)}$.
- Calculate the error signal $\delta_j^{(y_i)}$ for all units $j$ and each training example $y_{i}$. If $j$ is an output node, then $\delta_j^{(y_i)} = f'_j(s_j^{(y_i)})(\hat{y}_i - y_i)$. If $j$ is not an output node, then $\delta_j^{(y_i)} = f'_j(s_j^{(y_i)})\sum_{k\in\text{outs}(j)}\delta_k^{(y_i)} w_{j\rightarrow k}$.
- Update the weights with the rule $\Delta w_{i\rightarrow j} =-\frac{\eta}{N} \sum_{y_i} \delta_j^{(y_i)}z_i^{(y_i)}$.
Conclusions
Hopefully you've gained a full understanding of the backpropagation algorithm with this derivation. Although we've fully derived the general backpropagation algorithm in this chapter, it's still not in a form amenable to programming or scaling up. In the next post, I will go over the matrix form of backpropagation, along with a working example that trains a basic neural network on MNIST.